Python has a variety of visualization libraries, including seaborn, networkx, and vispy. Most Python visualization libraries are based wholly or partially on matplotlib, which often makes it the first option for making simple plots, and the last resort for making plots too complex to create in other libraries. In this matplotlib tutorial, we'll cover the basics of the library, and walk through making some intermediate visualizations. If you're looking for more great free data visualization resources, check out our complete guide to NumPy, pandas, and data visualization.
For this tutorial, we'll be working with a dataset of approximately 240,000 tweets about Hillary Clinton, Donald Trump, and Bernie Sanders, all of whom were―at one point or another―candidates for president of the United States. The data we're using was pulled from the Twitter Streaming API, and the csv of all 240,000 tweets we'll be working with can be downloaded here. If you want to scrape more data yourself, you can look here for the scraper code you can use to do that.
Exploring Tweets with Pandas
Before we get started with plotting, let's load in the data and do some basic exploration. We can use Pandas, a Python library for data analysis, to help us with this. In the below code, we'll:
- Import the Pandas library.
- Read
tweets.csvinto a Pandas DataFrame. - Print the first
5rows of the DataFrame.
import pandas as pd
tweets = pd.read_csv("tweets.csv")
tweets.head()
| id | id_str | user_location | user_bg_color | retweet_count | user_name | polarity | created | geo | user_description | user_created | user_followers | coordinates | subjectivity | text | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 729828033092149248 | Wheeling WV | 022330 | 0 | Jaybo26003 | 0.00 | 2016-05-10T00:18:57 | NaN | NaN | 2011-11-17T02:45:42 | 39 | NaN | 0.0 | Make a difference vote! WV Bernie Sanders Coul... |
| 1 | 2 | 729828033092161537 | NaN | C0DEED | 0 | brittttany_ns | 0.15 | 2016-05-10T00:18:57 | NaN | 18 // PSJAN | 2012-12-24T17:33:12 | 1175 | NaN | 0.1 | RT @HlPHOPNEWS: T.I. says if Donald Trump wins... |
| 2 | 3 | 729828033566224384 | NaN | C0DEED | 0 | JeffriesLori | 0.00 | 2016-05-10T00:18:57 | NaN | NaN | 2012-10-11T14:29:59 | 42 | NaN | 0.0 | You have no one to blame but yourselves if Tru... |
| 3 | 4 | 729828033893302272 | global | C0DEED | 0 | WhorunsGOVs | 0.00 | 2016-05-10T00:18:57 | NaN | Get Latest Global Political news as they unfold | 2014-02-16T07:34:24 | 290 | NaN | 0.0 | 'Ruin the rest of their lives': Donald Trump c... |
| 4 | 5 | 729828034178482177 | California, USA | 131516 | 0 | BJCG0830 | 0.00 | 2016-05-10T00:18:57 | NaN | Queer Latino invoking his 1st amendment privil... | 2009-03-21T01:43:26 | 354 | NaN | 0.0 | RT @elianayjohnson: Per source, GOP megadonor ... |
Here's a quick explanation of the important columns in the data:
id— the id of the row in the database (this isn't important).id_str— the id of the tweet on Twitter.user_location— the location the tweeter specified in their Twitter bio.user_bg_color— the background color of the tweeter's profile.user_name— the Twitter username of the tweeter.polarity— the sentiment of the tweet, from-1, to1.1indicates strong positivity,-1strong negativity.created— when the tweet was sent.user_description— the description the tweeter specified in their bio.user_created— when the tweeter created their account.user_follower— the number of followers the tweeter has.text— the text of the tweet.subjectivity— the subjectivity or objectivity of the tweet.0is very objective,1is very subjective.
Generating a Candidates Column
Most of the interesting things we can do with this dataset involve comparing the tweets about one candidate to the tweets about another candidate. For example, we could compare how objective tweets about Donald Trump are to how objective tweets about Bernie Sanders are. In order to accomplish this, we first need to generate a column that tells us what candidates are mentioned in each tweet. In the below code, we'll:
- Create a function that finds what candidate names occur in a piece of text.
- Use the apply method on DataFrames to generate a new column called
candidatethat contains what candidate(s) the tweet mentions.
def get_candidate(row):
candidates = []
text = row["text"].lower()
if "clinton" in text or "hillary" in text:
candidates.append("clinton")
if "trump" in text or "donald" in text:
candidates.append("trump")
if "sanders" in text or "bernie" in text:
candidates.append("sanders")
return ",".join(candidates)
tweets["candidate"] = tweets.apply(get_candidate,axis=1)
Making the First Plot
Now that we have the preliminaries out the way, we're ready to draw our first plot using matplotlib. In matplotlib, drawing a plot involves:
- Creating a Figure to draw plots into.
- Creating one or more Axes objects to draw the plots.
- Showing the figure, and any plots inside, as an image.
Because of its flexible structure, you can draw multiple plots into a single image in matplotlib. Each Axes object represents a single plot, like a bar plot or a histogram. This may sound complicated, but matplotlib has convenience methods that do all the work of setting up a Figure and Axes object for us.
Importing matplotlib
In order to use matplotlib, you'll need to first import the library using import matplotlib.pyplot as plt. If you're using Jupyter notebook, you can setup matplotlib to work inside the notebook using %matplotlib inline.
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
We import matplotlib.pyplot because this contains the plotting functions of matplotlib. We give it the plt alias for convenience, so it's faster to make plots.
Making a Bar Plot
Once we've imported matplotlib, we can make a bar plot of how many tweets mentioned each candidate. In order to do this, we'll:
- Use the value_counts method on Pandas Series to count up how many tweets mention each candidate.
- Use
plt.barto create a bar plot. We'll pass in a list of numbers from0to the number of unique values in thecandidatecolumn as the x-axis input, and the counts as the y-axis input. - Display the counts so we have more context about what each bar represents.
counts = tweets["candidate"].value_counts()
plt.bar(range(len(counts)), counts)
plt.show()
print(counts)
trump 119998
clinton,trump 30521
25429
sanders 25351
clinton 22746
clinton,sanders 6044
clinton,trump,sanders 4219
trump,sanders 3172
Name: candidate, dtype: int64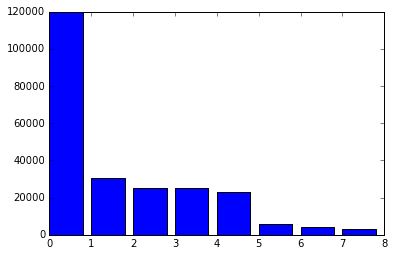
It's pretty surprising how many more tweets are about Trump than are about Sanders or Clinton! You may notice that we don't create a Figure, or any Axes objects. This is because calling plt.bar will automatically setup a Figure and a single Axes object, representing the bar plot. Calling the plt.show method will show anything in the current figure. In this case, it shows an image containing a bar plot. matplotlib has a few methods in the pyplot module that make creating common types of plots faster and more convenient because they automatically create a Figure and an Axes object. The most widely used are:
- plt.bar — creates a bar chart.
- plt.boxplot — makes a box and whisker plot.
- plt.hist — makes a histogram.
- plt.plot — creates a line plot.
- plt.scatter — makes a scatter plot.
Calling any of these methods will automatically setup Figure and Axes objects, and draw the plot. Each of these methods has different parameters that can be passed in to modify the resulting plot.
Customizing Plots
Now that we've made a basic first plot, we can move on to creating a more customized second plot. We'll make a basic histogram, then modify it to add labels and other information. One of the things we can look at is the age of the user accounts that are tweeting. We'll be able to find if there differences in when the accounts of users who tweet about Trump and when the accounts of users who tweet about Clinton were created. One candidate having more user accounts created recently might imply some kind of manipulation of Twitter with fake accounts. In the code below, we'll:
- Convert the
createdanduser_createdcolumns to the Pandas datetime type. - Create a
user_agecolumn that is the number of days since the account was created. - Create a histogram of user ages.
- Show the histogram.
from datetime import datetime
tweets["created"] = pd.to_datetime(tweets["created"])
tweets["user_created"] = pd.to_datetime(tweets["user_created"])
tweets["user_age"] = tweets["user_created"].apply(lambda x: (datetime.now() - x).total_seconds() / 3600 / 24 / 365)
plt.hist(tweets["user_age"])
plt.show()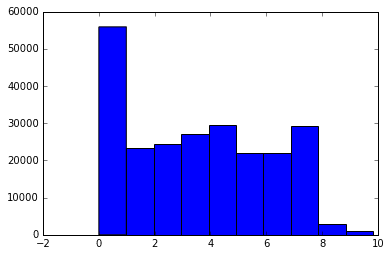
Adding Labels
We can add titles and axis labels to matplotlib plots. The common methods with which to do this are:
- plt.title — adds a title to the plot.
- plt.xlabel — adds an x-axis label.
- plt.ylabel — adds a y-axis label.
Since all of the methods we discussed before, like bar and hist, automatically create a Figure and a single Axes object inside the figure, these labels will be added to the Axes object when the method is called. We can add labels to our previous histogram using the above methods. In the code below, we'll:
- Generate the same histogram we did before.
- Draw a title onto the histogram.
- Draw an x axis label onto the histogram.
- Draw a y axis label onto the histogram.
- Show the plot.
plt.hist(tweets["user_age"])
plt.title("Tweets mentioning candidates")
plt.xlabel("Twitter account age in years")
plt.ylabel("# of tweets")
plt.show()
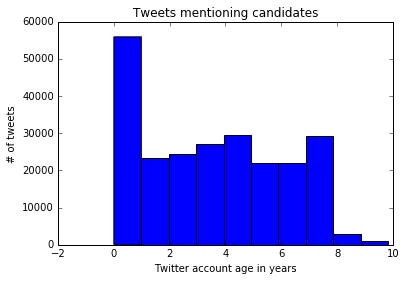
Making a Stacked Histogram
The current histogram does a nice job of telling us the account age of all tweeters, but it doesn't break it down by candidate, which might be more interesting. We can leverage the additional options in the hist method to create a stacked histogram. In the below code, we'll:
- Generate three Pandas series, each containing the
user_agedata only for tweets about a certain candidate. - Make a stacked histogram by calling the
histmethod with additional options.- Specifying a list as the input will plot three sets of histogram bars.
- Specifying
stacked=Truewill stack the three sets of bars. - Adding the
labeloption will generate the correct labels for the legend.
- Call the plt.legend method to draw a legend in the top right corner.
- Add a title, x axis, and y axis labels.
- Show the plot.
cl_tweets = tweets["user_age"][tweets["candidate"] == "clinton"]
sa_tweets = tweets["user_age"][tweets["candidate"] == "sanders"]
tr_tweets = tweets["user_age"][tweets["candidate"] == "trump"]
plt.hist([cl_tweets, sa_tweets, tr_tweets],
stacked=True,
label=["clinton", "sanders", "trump"]
)
plt.legend()
plt.title("Tweets mentioning each candidate")plt.xlabel("Twitter account age in years")
plt.ylabel("# of tweets")
plt.show()
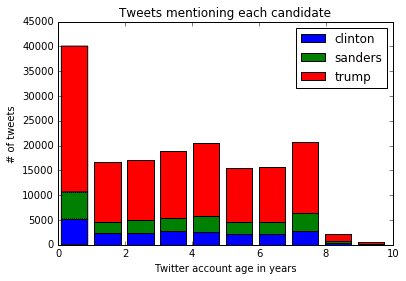
Annotating the Histogram
We can take advantage of matplotlibs ability to draw text over plots to add annotations. Annotations point to a specific part of the chart, and let us add a snippet describing something to look at. In the code below, we'll make the same histogram as we did above, but we'll call the plt.annotate method to add an annotation to the plot.
plt.hist([cl_tweets, sa_tweets, tr_tweets ],
stacked=True,
label=["clinton", "sanders", "trump"]
)
plt.legend()
plt.title("Tweets mentioning each candidate")
plt.xlabel("Twitter account age in years")
plt.ylabel("# of tweets")
plt.annotate('More Trump tweets', xy=(1, 35000), xytext=(2, 35000),
arrowprops=dict(facecolor='black'))
plt.show()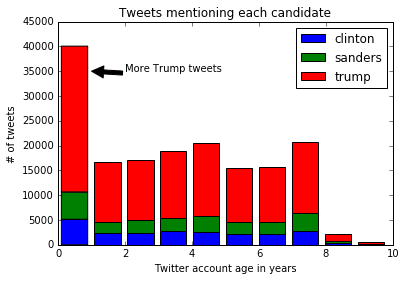
Here's a description of what the options passed into annotate do:
xy— determines thexandycoordinates where the arrow should start.xytext— determines thexandycoordinates where the text should start.arrowprops— specify options about the arrow, such as color.
As you can see, there are significantly more tweets about Trump then there are about other candidates, but there doesn't look to be a significant difference in account ages.
Multiple Subplots
So far, we've been using methods like plt.bar and plt.hist, which automatically create a Figure object and an Axes object. However, we can explicitly create these objects when we want more control over our plots. One situation in which we would want more control is when we want to put multiple plots side by side in the same image. We can generate a Figure and multiple Axes objects by calling the plt.subplots methods. We pass in two arguments, nrows, and ncols, which define the layout of the Axes objects in the Figure. For example, plt.subplots(nrows=2, ncols=2) will generate 2x2 grid of Axes objects. plt.subplots(nrows=2, ncols=1) will generate a 2x1 grid of Axes objects, and stack the two Axes vertically. Each Axes object supports most of the methods from pyplot. For instance, we could call the bar method on an Axes object to generate a bar chart.
Extracting Colors
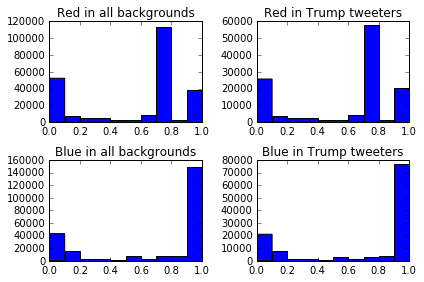
We'll generate 4 plots that show the amount of the colors red and blue in the Twitter background colors of users tweeting about Trump. This may show if tweeters who identify as Republican are more likely to put red in their profile. First, we'll generate two columns, red and blue, that tell us how much of each color is in each tweeter's profile background, from 0 to 1. In the code below, we'll:
- Use the
applymethod to go through each row in theuser_bg_colorcolumn, and extract how much red is in it. - Use the
applymethod to go through each row in theuser_bg_colorcolumn, and extract how much blue is in it.
import matplotlib.colors as colors
tweets["red"] = tweets["user_bg_color"].apply(lambda x: colors.hex2color('#{0}'.format(x))[0])
tweets["blue"] = tweets["user_bg_color"].apply(lambda x: colors.hex2color('#{0}'.format(x))[2])Creating the Plot
Once we have the data setup, we can create the plots. Each plot will be a histogram showing how many tweeters have a profile background containing a certain amount of blue or red. In the below code, we:
- Generate a Figure and multiple Axes with the
subplotsmethod. The axes will be returned as an array. - The axes are returned in a 2x2 NumPy array. We extract each individual Axes object by using the flat property of arrays. This gives us
4Axes objects we can work with. - Plot a histogram in the first Axes using the hist method.
- Set the title of the first Axes to
Red in all backgroundsusing the set_title method. This performs the same function asplt.title. - Plot a histogram in the second Axes using the hist method.
- Set the title of the second Axes to
Red in Trump tweetersusing the set_title method. - Plot a histogram in the third Axes using the hist method.
- Set the title of the third Axes to
Blue in all backgroundsusing the set_title method. This performs the same function asplt.title. - Plot a histogram in the fourth Axes using the hist method.
- Set the title of the fourth Axes to
Blue in Trump tweetersusing the set_title method. - Call the plt.tight_layout method to reduce padding in the graphs and fit all the elements.
- Show the plot.
fig, axes = plt.subplots(nrows=2, ncols=2)
ax0, ax1, ax2, ax3 = axes.flat
ax0.hist(tweets["red"])
ax0.set_title('Red in backgrounds')
ax1.hist(tweets["red"][tweets["candidate"] == "trump"].values)
ax1.set_title('Red in Trump tweeters')
ax2.hist(tweets["blue"])
ax2.set_title('Blue in backgrounds')
ax3.hist(tweets["blue"][tweets["candidate"] == "trump"].values)
ax3.set_title('Blue in Trump tweeters')
plt.tight_layout()
plt.show()
Removing Common Background Colors
Twitter has default profile background colors that we should probably remove so we can cut through the noise and generate a more accurate plot. The colors are in hexadecimal format, where code>#000000 is black, and #ffffff is white. Here's how to find the most common colors in background colors:
tweets["user_bg_color"].value_counts()
C0DEED 108977
000000 31119
F5F8FA 25597
131516 7731
1A1B1F 5059
022330 4300
0099B9 3958Now, we can remove the three most common colors, and only plot out users who have unique background colors. The code below is mostly what we did earlier, but we'll:
- Remove
C0DEED,000000, andF5F8FAfromuser_bg_color. - Create a function with out plotting logic from the last chart inside.
- Plot the same
4plots from before without the most common colors inuser_bg_color.
tc = tweets[~tweets["user_bg_color"].isin(["C0DEED", "000000", "F5F8FA"])]
def create_plot(data):
fig, axes = plt.subplots(nrows=2, ncols=2)
ax0, ax1, ax2, ax3 = axes.flat
ax0.hist(data["red"])
ax0.set_title('Red in backgrounds')
ax1.hist(data["red"][data["candidate"] == "trump"].values)
ax1.set_title('Red in Trump tweets')
ax2.hist(data["blue"])
ax2.set_title('Blue in backgrounds')
ax3.hist(data["blue"][data["candidate"] == "trump"].values)
ax3.set_title('Blue in Trump tweeters')
plt.tight_layout()
plt.show()
create_plot(tc)
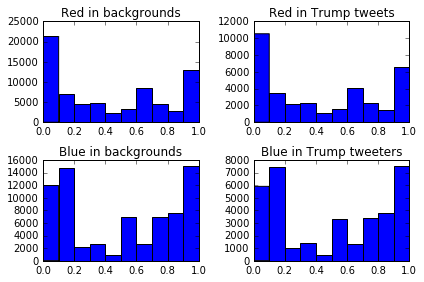
As you can see, the distribution of blue and red in background colors for users that tweeted about Trump is almost identical to the distribution for all tweeters.
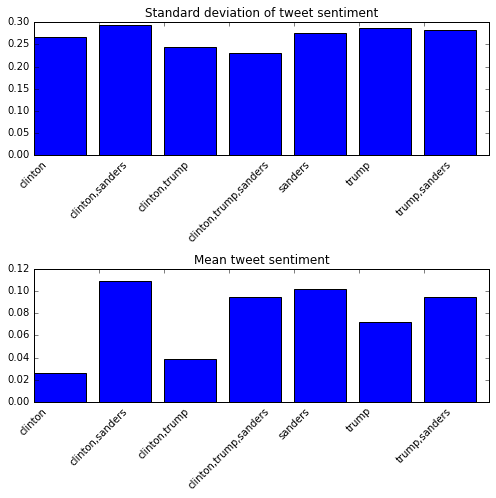
Plotting Sentiment
We generated sentiment scores for each tweet using TextBlob, which are stored in the polarity column. We can plot the mean value for each candidate, along with the standard deviation. The standard deviation will tell us how wide the variation is between all the tweets, whereas the mean will tell us how the average tweet is. In order to do this, we can add 2 Axes to a single Figure, and plot the mean of polarity in one, and the standard deviation in the other. Because there are a lot of text labels in these plots, we'll need to increase the size of the generated figure to match. We can do this with the figsize option in the plt.subplots method. The code below will:
- Group tweets by candidate, and compute the mean and standard deviation for each numerical column (including
polarity). - Create a Figure that's
7inches by7inches, with 2 Axes objects, arranged vertically. - Create a bar plot of the standard deviation the first Axes object.
- Set the tick labels using the set_xticklabels method, and rotate the labels
45degrees using therotationargument. - Set the title.
- Set the tick labels using the set_xticklabels method, and rotate the labels
- Create a bar plot of the mean on the second Axes object.
- Set the tick labels.
- Set the title.
- Show the plot.
gr = tweets.groupby("candidate").agg([np.mean, np.std])
fig, axes = plt.subplots(nrows=2, ncols=1, figsize=(7, 7))
ax0, ax1 = axes.flat
std = gr["polarity"]["std"].iloc[1:]
mean = gr["polarity"]["mean"].iloc[1:]
ax0.bar(range(len(std)), std)
ax0.set_xticklabels(std.index, rotation=45)
ax0.set_title('Standard deviation of tweet sentiment')
ax1.bar(range(len(mean)), mean)
ax1.set_xticklabels(mean.index, rotation=45)
ax1.set_title('Mean tweet sentiment')
plt.tight_layout()
plt.show()
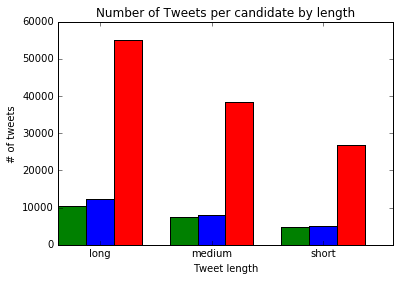
Generating a Side by Side Bar Plot
We can plot tweet length by candidate using a bar plot. We'll first split the tweets into short, medium, and long tweets. Then, we'll count up how many tweets mentioning each candidate fall into each group. Then, we'll generate a bar plot with bars for each candidate side by side.
Generating Tweet Lengths
To plot the tweet lengths, we'll first have to categorize the tweets, then figure out how many tweets by each candidate fall into each bin. In the code below, we'll:
- Define a function to mark a tweet as
shortif it's less than100characters,mediumif it's100to135characters, andlongif it's over135characters. - Use
applyto generate a new columntweet_length. - Figure out how many tweets by each candidate fall into each group.
def tweet_lengths(text):
if len(text) < 100:
return "short"
elif 100 <= len(text) <= 135:
return "medium"
else:
return "long"
tweets["tweet_length"] = tweets["text"].apply(tweet_lengths)
tl = {}
for candidate in ["clinton", "sanders", "trump"]:
tl[candidate] = tweets["tweet_length"][tweets["candidate"] == candidate].value_counts()
Plotting
Now that we have the data we want to plot, we can generate our side by side bar plot. We'll use the bar method to plot the tweet lengths for each candidate on the same axis. However, we'll use an offset to shift the bars to the right for the second and third candidates we plot. This will give us three category areas, short, medium, and long, with one bar for each candidate in each area. In the code below, we:
- Create a Figure and a single Axes object.
- Define the
widthfor each bar,.5. - Generate a sequence of values,
x, that is0,2,4. Each value is the start of a category, such asshort,medium, andlong. We put a distance of2between each category so we have space for multiple bars. - Plot
clintontweets on the Axes object, with the bars at the positions defined byx. - Plot
sanderstweets on the Axes object, but addwidthtoxto move the bars to the right. - Plot
trumptweets on the Axes object, but addwidth * 2toxto move the bars to the far right. - Set the axis labels and title.
- Use
set_xticksto move the tick labels to the center of each category area. - Set tick labels.
fig, ax = plt.subplots()
width = .5
x = np.array(range(0, 6, 2))
ax.bar(x, tl["clinton"], width, color='g')
ax.bar(x + width, tl["sanders"], width, color='b')
ax.bar(x + (width * 2), tl["trump"], width, color='r')
ax.set_ylabel('# of tweets')
ax.set_title('Number of Tweets per candidate by length')
ax.set_xticks(x + (width * 1.5))
ax.set_xticklabels(('long', 'medium', 'short'))
ax.set_xlabel('Tweet length')
plt.show()
Next Steps
You can make quite a few plots next:
- Analyze user descriptions, and see how description length varies by candidate.
- Explore time of day — do supporters of one candidate tweet more at certain times?
- Explore user location, and see which states tweet about which candidates the most.
- See what kinds of usernames tweet more about what kinds of candidates.
- Do more digits in usernames correlate with support for a candidate?
- Which candidate has the most all caps supporters?
- Scrape more data, and see if the patterns shift.
We've learned quite a bit about how matplotlib generates plots, and gone through a good bit of the dataset. If you want to find out more about matplotlib and data visualization you can checkout our interactive Data Analysis and Visualization with Python skill path. The first lesson in each course is free!
I hope this matplotlib tutorial was helpful, and if you do any interesting analysis with this data please get in touch — we'd love to hear from you!